/
April 3, 2026
/
#
Min Read
When Your Fleet Data Is Talking, But Nobody's Listening
AI Anomaly Detection for Connected Vehicles: Catching What Rules-Based Systems Miss
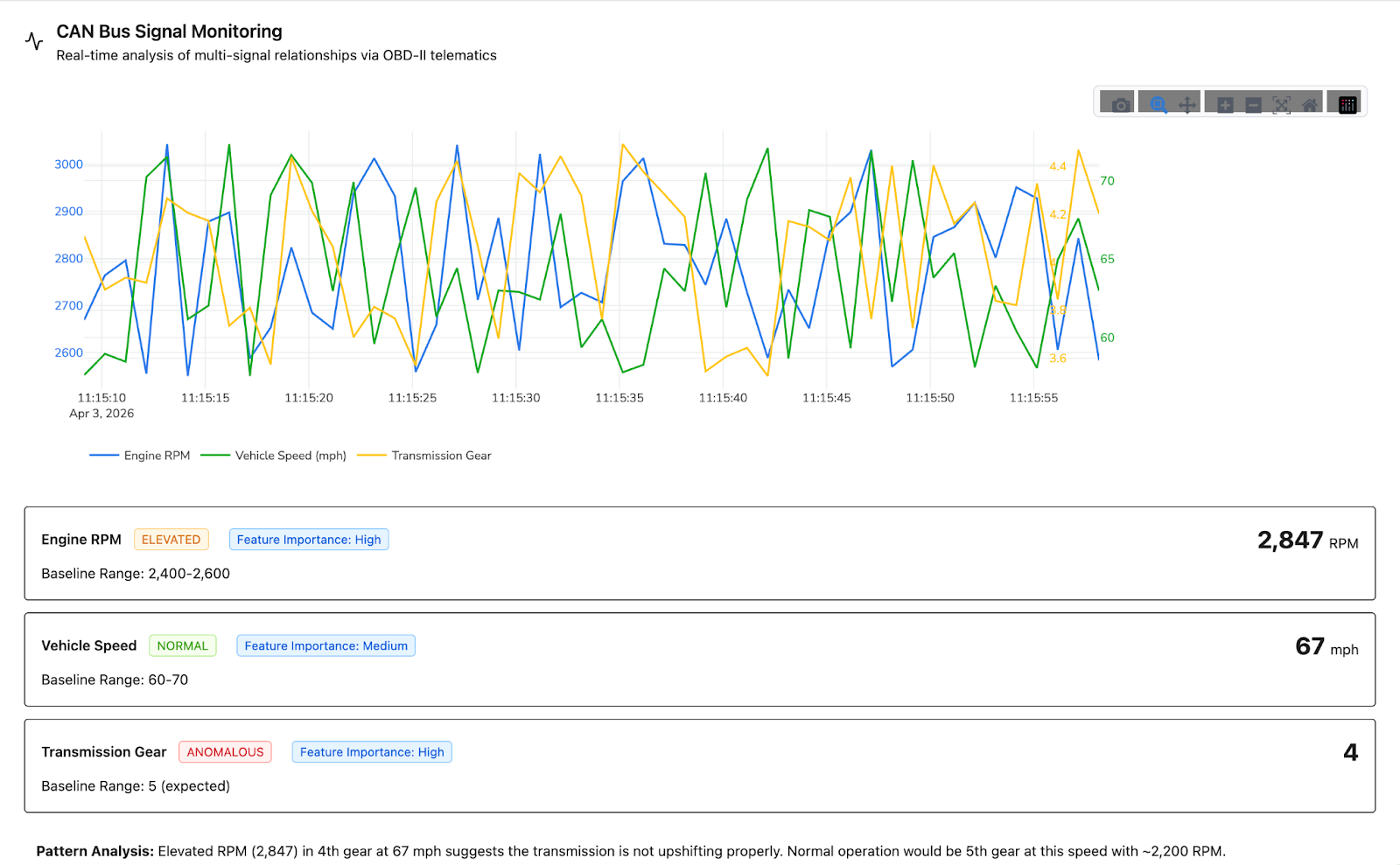
Today’s connected vehicle generates multiple gigabytes of data per hour - voltage readings, thermal profiles, inverter behavior, CAN bus traffic, charging patterns, tire pressures, and thousands of other signals streaming continuously to the cloud. Multiply that across a fleet of 10,000 vehicles and you're looking at petabytes of telemetry per year. Somewhere in that ocean of data, a battery module is quietly degrading. A motor controller is drifting outside its normal operating envelope. A software update introduced a subtle regression in braking calibration that only manifests under specific ambient conditions.
The problem isn't a lack of data. It's that pinpointing meaningful signals is getting increasingly harder.
The Limits of Threshold-Based Monitoring
Most OEM and fleet engineering teams still rely on rules-based diagnostic systems - static DTC thresholds, hardcoded alert boundaries, and manual review of flagged events. These systems work well for known failure modes. If coolant temperature exceeds 110°C, trigger an alert. If battery cell voltage drops below 2.5V, flag the pack. Straightforward.
But the failures that hurt most aren't the ones you've already written rules for. They're the ones you haven't seen yet.
Consider what happened with Volkswagen's ID.4 in 2025: a shifted electrode condition in battery cells supplied by SK Battery America led to multiple thermal events and ultimately a recall of over 44,000 vehicles. The root cause wasn't a failure mode the BMS was explicitly monitoring for - it required physical teardown analysis, CT scans, and months of cross-supplier investigation to isolate. By the time countermeasures were in place, the damage to the brand and the cost of the recall were already locked in.
This pattern repeats across the industry. Li Auto recalled over 11,000 Mega EVs after tracing a thermal runaway risk to insufficient coolant corrosion protection - a subtle chemical degradation issue that wouldn't trip a conventional diagnostic rule until it was far too late. The vehicles' cloud-based early warning system detected the incident, but the underlying degradation had been building quietly for months.
These aren't edge cases. They're the predictable consequence of relying on rules to catch problems that, by definition, don't have rules yet.
What Unsupervised Learning Actually Changes
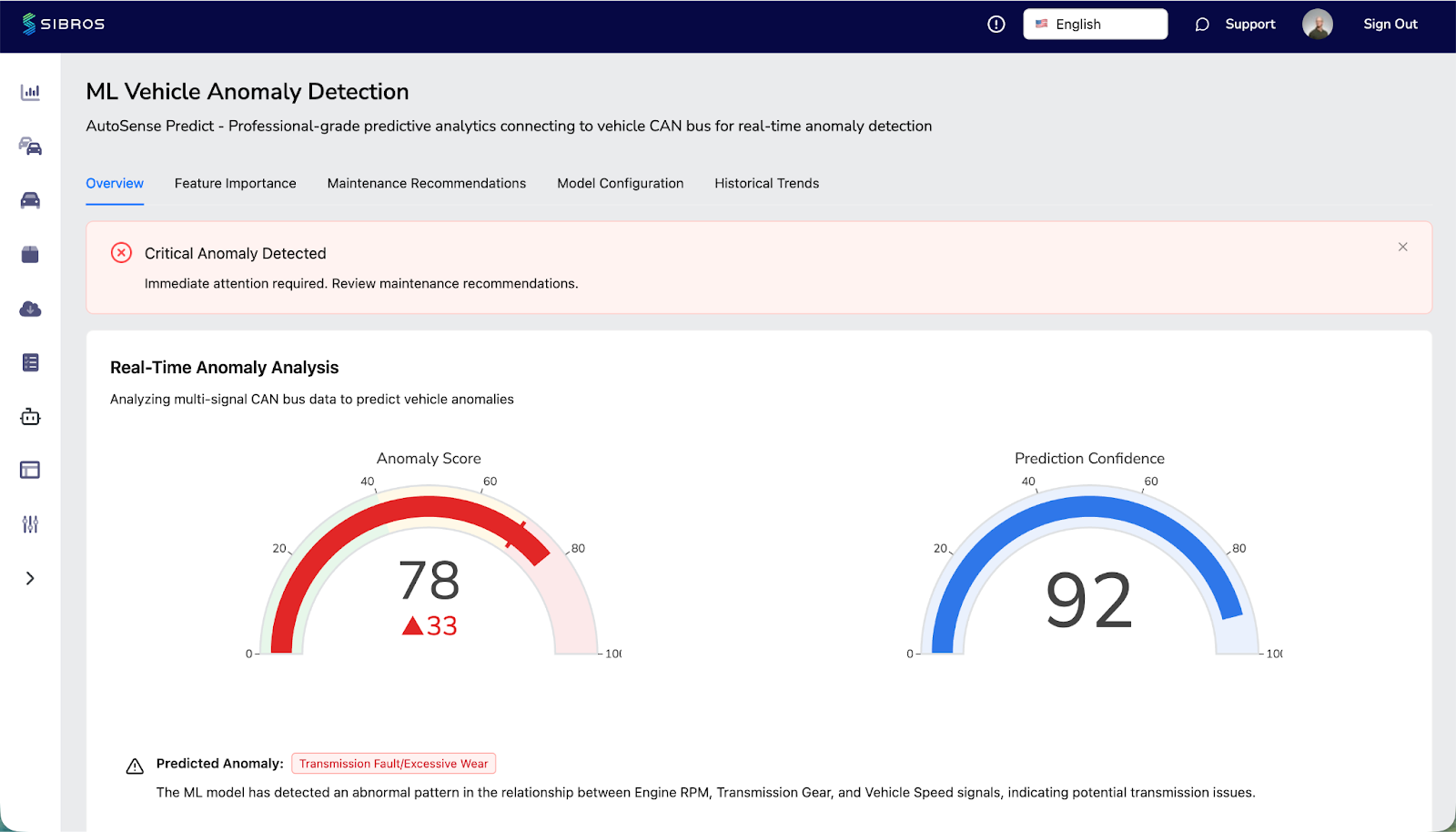
The shift happening now - and it's still early - is the application of unsupervised machine learning models to continuous fleet telemetry. Unlike supervised models that require labeled training data ("here are 500 examples of battery failures"), unsupervised approaches learn what normal looks like for a given vehicle, component, or fleet segment, and then flag deviations from that baseline.
This matters for connected vehicle operations in a few specific ways:
Battery health degradation. Cell-level voltage imbalance, capacity fade patterns, and thermal behavior during charging cycles all produce subtle distributional shifts long before a BMS threshold is breached. Anomaly detection can surface these shifts at the fleet level - identifying which pack configurations, suppliers, or firmware versions are trending toward accelerated degradation. With EV battery warranties extending to 8–10 years and regulations like China's GB38031-2025 now mandating zero-fire outcomes during thermal runaway events, early detection isn't optional. It's a liability issue.
Post-OTA validation. Software-defined vehicles push updates frequently - sometimes weekly. Each update has the potential to introduce behavioral regressions that only appear under specific real-world conditions (highway speeds in cold weather, high-load towing, rapid charge-discharge cycling). Anomaly detection applied to pre- and post-update telemetry baselines can flag these regressions across the fleet before they generate warranty claims or customer complaints.
Component-level drift in mixed fleets. Commercial truck and bus operators running mixed fleets - different makes, model years, powertrain types - face a data normalization challenge that compounds the detection problem. An anomaly detection platform that builds adaptive baselines per vehicle segment can surface, for example, that a specific turbocharger actuator is exhibiting abnormal behavior across a cohort of vehicles that share a common supplier, while filtering out the normal variance between a 2023 diesel and a 2025 BEV in the same fleet.
Energy storage systems beyond automotive. The same unsupervised approach applies to stationary battery energy storage systems (BESS), where thermal management and cell degradation patterns share fundamental characteristics with EV packs but operate under different duty cycles and environmental conditions.
The Cost of Late Detection
The economics are blunt. Unplanned downtime for a single commercial truck costs between $448 and $760 per day in lost revenue - and that's before you account for towing, emergency parts, driver wages, missed SLAs, and downstream schedule disruption. Industry data shows fleets average 8.7 days of unplanned downtime per vehicle per year. Reactive repairs cost 3–9x more than the same service performed proactively.
For passenger vehicle OEMs, the calculus is different but equally painful. A safety recall involving battery thermal risk doesn't just carry direct remediation costs - it drives insurance premiums, triggers regulatory scrutiny, erodes residual values, and generates the kind of headlines that take years to recover from.
The gap between "we detected the anomaly at week 3" and "we discovered the failure at month 9" is measured in millions of dollars and, in some cases, in safety outcomes.
What to Look For in a Detection Platform
Not all anomaly detection is created equal. When evaluating solutions for connected vehicle operations, a few capabilities separate useful tools from noise generators:
Adaptive baselines that adjust to evolving vehicle conditions - not static thresholds that generate false positives every time ambient temperature changes or a vehicle enters a new duty cycle. The goal is fewer, higher-signal alerts, not more alerts.
Drift monitoring that tracks shifts in data distributions and model performance over time. Vehicle software and hardware evolve continuously. A model trained on last quarter's fleet behavior needs to recognize when its own assumptions are stale.
Root-cause context that gives engineers a starting point for investigation - not just "anomaly detected on VIN 12345" but correlated signals, temporal patterns, and cohort-level context that accelerate diagnosis.
Feedback loops that allow engineering teams to confirm, dismiss, or reclassify detections, feeding that judgment back into the model to improve precision over time.
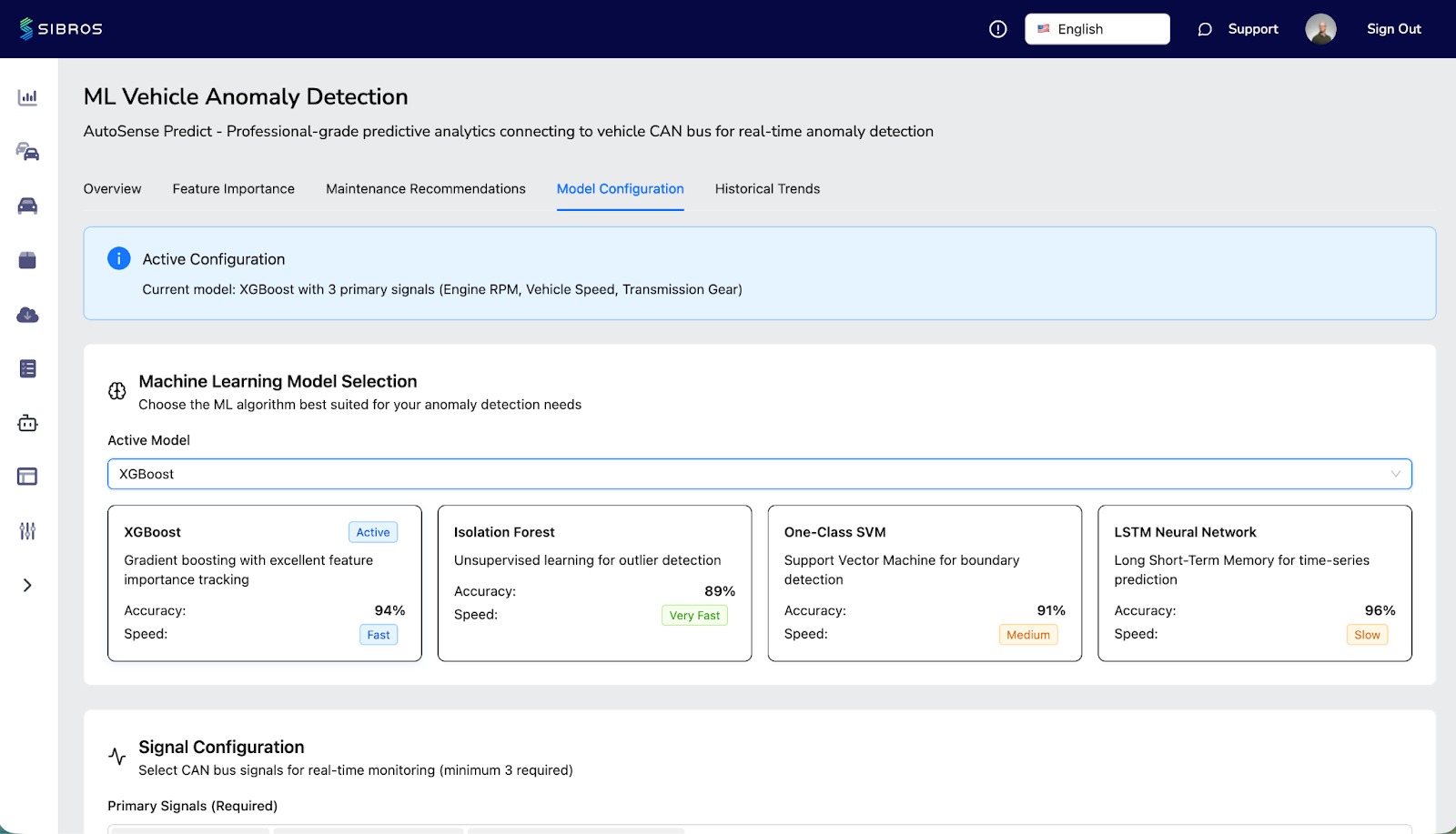
The ML Anomaly Detection Platform, available on the Sibros Marketplace, is built around these principles. It applies unsupervised learning to continuously monitor fleet telemetry, surfacing early deviations in vehicle, battery, and component behavior without requiring pre-labeled failure data. Adaptive baselines reduce alert fatigue. Drift monitoring keeps the system relevant as your fleet evolves. And integrated root-cause hints give engineering and operations teams a faster path from detection to resolution.
Learn more on the Sibros Marketplace.



Related posts

Latest Posts

R156 Readiness Tracker by Sibros automates evidence collection and ECU readiness monitoring to simplify regulatory compliance under UNECE R156.