/
February 19, 2026
/
#
Min Read
Unplanned Downtime Is Predictable. That's the Whole Point of Predictive Maintenance
Fleet operators and OEMs have spent the last decade investing heavily in connected software defined vehicle infrastructure. These modern vehicles generate more data than ever before - fault codes, sensor streams, location pings, usage telemetry. Yet a persistent irony remains: organizations drowning in data are still caught off guard by breakdowns, still chasing repeat faults, and still scrambling for parts that should have been on a shelf three weeks earlier. The problem isn't data. It's the gap between raw signals and actionable intelligence.
The Reactive Maintenance Trap
The cost gap between reactive and preventive maintenance is well-documented across the industry - emergency repairs run 3 to 9 times more than the same work performed on a schedule, a multiplier driven not just by labor and parts, but by towing fees, expedited shipping, and revenue lost while vehicles sit idle. For large fleets, those daily losses compound fast: Ryder and ServiceUp consistently put unplanned downtime costs at $448–$760 per vehicle per day.
Despite this, most service operations still function in a largely reactive mode - responding to fault codes after they fire, diagnosing issues from incomplete DTC histories, and relying on technician intuition to determine whether a component is genuinely failing or throwing a nuisance code.
The pattern is familiar: a vehicle enters a service center, a fault is cleared, the vehicle returns to service, and the same fault reappears two weeks later. Repeat faults are one of the most significant drivers of warranty cost and customer dissatisfaction across both commercial truck and passenger vehicle segments. Studies suggest repeat repair rates hover between 15–25% across the industry - a substantial and largely addressable inefficiency that starts with better signal-to-decision workflows.
Risk Scoring Changes the Conversation
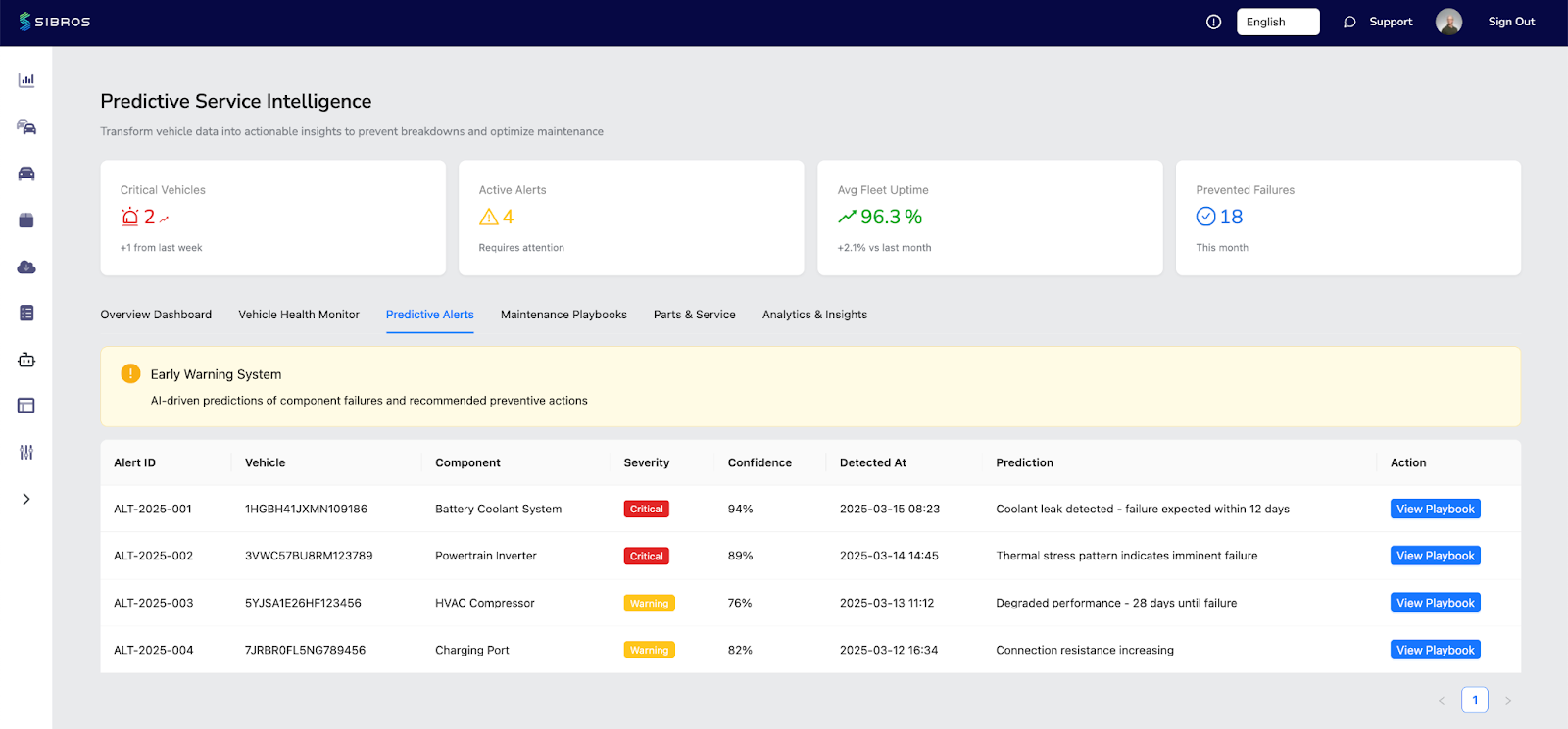
One of the more practical shifts in modern fleet diagnostics is the move from fault-centric monitoring to risk-centric prioritization. Rather than treating every DTC equally, risk scoring aggregates fault frequency, component history, vehicle utilization, and failure pattern data to assign a reliability score at the VIN or component level.
This reframing has real operational value. A service manager looking at 200 active vehicles doesn't need 200 separate inputs - they need to know which 12 require attention this week, which components across the fleet are trending toward failure, and which repairs are likely to recur without a deeper intervention. Risk scoring makes that prioritization tractable.
Fault heatmaps extend this further by visualizing where problems concentrate across a fleet - by geography, route, vehicle age, or spec configuration. When a particular fault clusters around a specific model year or duty cycle, that's a signal worth investigating before it becomes a field campaign.
Guided Workflows: Closing the Loop Between Data and Action
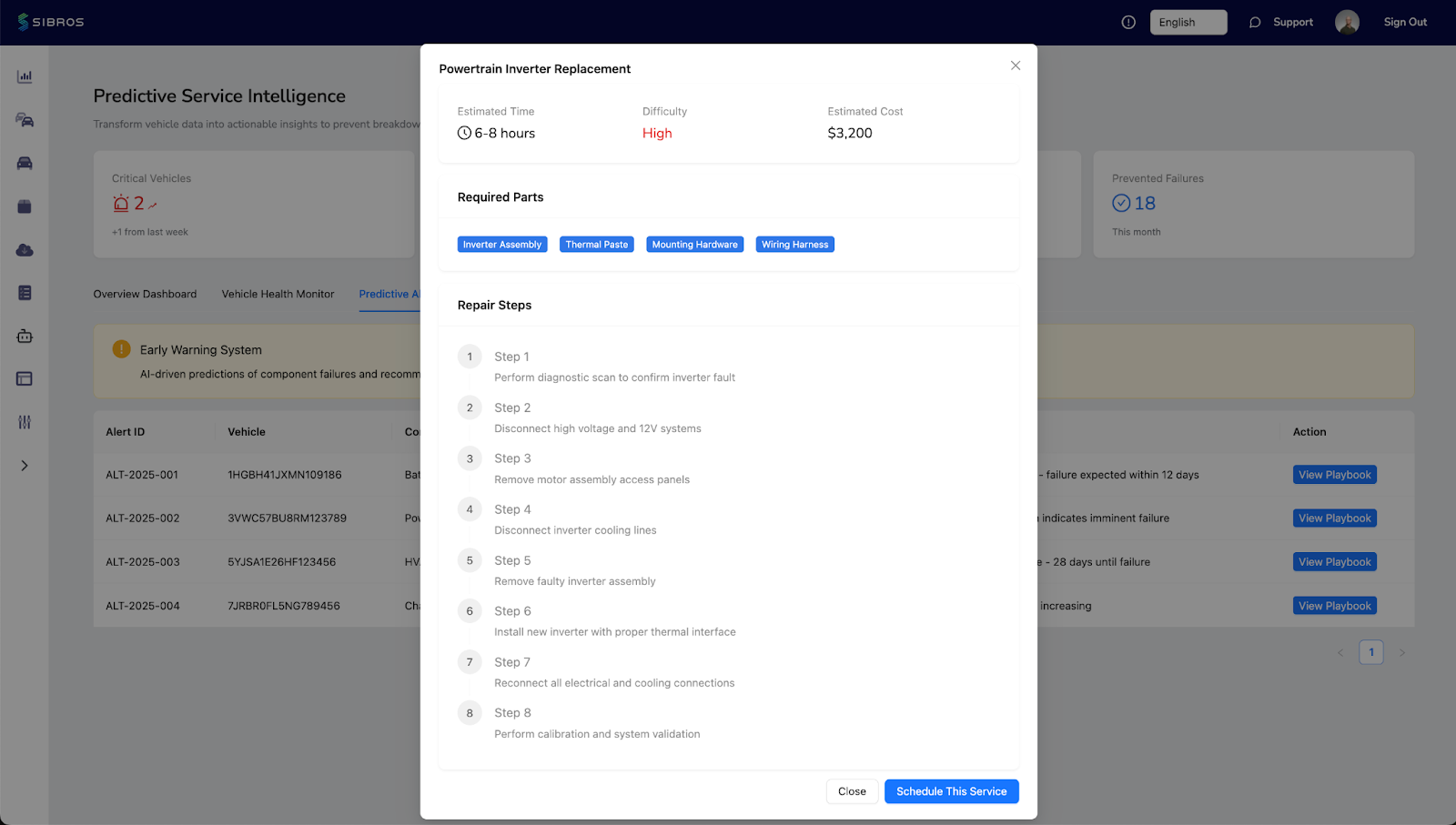
Early warning systems and repair playbooks address a different but equally important failure mode: the gap between knowing something is wrong and knowing what to do about it. Even with good diagnostic data, technicians face inconsistent repair outcomes when procedures aren't standardized and parts recommendations aren't tied to actual fault patterns.
Guided repair workflows - step-by-step procedures informed by fleet-wide failure data and parts history - reduce diagnostic variability and improve first-time fix rates. When paired with predictive parts recommendations, they also help service teams get ahead of supply delays. Parts availability is increasingly a bottleneck in fleet maintenance; knowing 60 days out that a specific component is trending toward failure across a segment of the fleet creates meaningful procurement lead time.
Uptime Forecasting as a Planning Tool
For bus operators, logistics fleets, and commercial truck OEMs managing service contracts, uptime forecasting is becoming a core planning input rather than a nice-to-have. Predicting vehicle availability trends - based on maintenance cycles, fault histories, and utilization patterns - allows dispatch and operations teams to plan around maintenance windows rather than react to unexpected removals from service.
The downstream effect on customer satisfaction is tangible. Fleet customers buying uptime commitments need predictability. OEMs and dealers who can provide data-backed availability forecasts are better positioned to support those commitments and differentiate on service quality.
From Signal to Action
The connected vehicle ecosystem has matured to the point where the competitive advantage is no longer in collecting data - it's in operationalizing it. The organizations reducing reactive maintenance, lowering warranty exposure, and improving time-to-resolution are the ones that have built systems connecting telemetry to decisions at every level: engineering, service, and operations. That's easier said than built from scratch.
The Predictive Service Intelligence app on the Sibros Marketplace can arm fleet service operators with intelligent risk scoring, fault heatmaps, early warnings, repair playbooks, parts recommendations, and uptime forecasting as a connected-vehicle solution - without the months of custom development. Learn more at marketplace.sibros.tech.



Related posts

Latest Posts


R156 Readiness Tracker by Sibros automates evidence collection and ECU readiness monitoring to simplify regulatory compliance under UNECE R156.